
Stata lineare Regression Voraussetzungen
Die lineare Regression ist eine der am häufigsten eingesetzten Statistischen Methoden. Bei Durchführung der Regression ist zu beachten, dass sie einige Voraussetzungen hat. Die Überprüfung dieser Voraussetzung ist häufig nachgefragtes Thema in der Statistik-Beratung, weshalb wir Ihnen hier eine Anleitung zur Verfügung stellen.
Insgesamt müssen bei der linearen Regression folgende Voraussetzungen geprüft werden:
- Keine Multikollinearität der unabhängigen Variablen
- Homoskedastizität der Residuen
- Normalverteilung der Residuen
- Keine Autokorrelation der Residuen
- Linearer Zusammenhang zwischen der abhängigen und den unabhängigen Variablen
In diesem Artikel demonstrieren wir die Prüfung der Regressionsvoraussetzungen anhand des Datensatzes auto. Dies ist ein sehr bekannter Beispieldatensatz, der in Stata vorinstalliert ist. Um den Datensatz zu laden, geben Sie in die Stata-Kommandozeile den folgenden Befehl ein:
sysuse auto,clear
Nach dem Ausführen des Befehls haben Sie den Datensatz geladen. Sehen Sie sich zunächst den Datensatz an. Geben Sie hierzu in die Kommandozeile den Befehl browse ein. Es öffnet sich nun die Datenansicht. Der Datensatz sieht folgendermaßen aus:
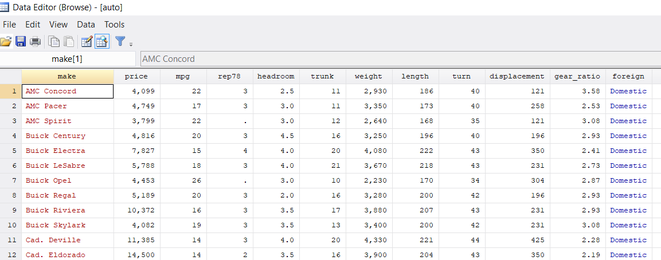
Der Datensatz enthält Informationen zu verschiedenen Automodellen. Man sieht z.B., dass die erste Zeile Daten über das Automodell AMC Concord und die zweite Zeile Informationen über AMC Pacer enthält.
In den Spalten des Datensatz sind verschiedene Informationen über die einzelnen Autos enthalten. Die Spalte price enthält z.B. den Preis der Autos. In der Spalte price ist z.B. zu sehen, dass das Auto AMC Concord einen Preis von 4099 $ hat.
Wir berechnen nun eine Regressionsanalyse mit diesem Datensatz. Hierzu verwenden wir die Variablen gear_ratio, weight, length und foreign.
Als abhängige Variable der Regression wird gear_ratio verwendet, als unabhängige Variablen weight, length und foreign. Somit untersuchen wir, ob die Variablen weight, length und foreign einen Einfluss auf die Variable gear_ratio aufweisen.
Ob dieses Regressionsmodell inhaltlich einen Sinn ergibt, ist in diesem Beispiel für uns nicht relevant, da es in diesem Artikel nur um die Prüfung der Regressionsvoraussetzungen geht.
Um das Regressionsmodell zu berechnen, geben Sie in die Stata-Konsole den folgenden Befehl ein:
reg gear_ratio weight length i.foreign
Beachten Sie: Da die Variable foreign eine kategorielle Variable ist, haben wir in diesem Befehl i.foreign geschrieben. Immer wenn Sie eine kategorielle Variable als unabhängige Variable eines Regressionsmodells verwenden möchten, müssen Sie die Schreibweise i. für diese Variable verwenden.
Nach Ausführung des Befehls erhalten Sie zunächst den Output des Regressionsmodells. Dieser sollte folgendermaßen aussehen:

Wir überspringen die Interpretation dieses Outputs, da wir uns in diesem Artikel auf die Prüfung der Regressionsvorraussetzungen konzentrieren möchten.
1. Multikollinearität mittels VIF prüfen in Stata
Die erste Voraussetzung besagt, dass keine Multikollinearität vorliegen darf. Das bedeutet, die Korrelationen zwischen den unabhängigen Variablen der Regression dürfen nicht "zu hoch" sein.
Um zu entscheiden, was "zu hoch" ist gibt es einige Methoden von denen das VIF (Variance Inflation Factor) die bekannteste ist. Um für unsere Regression die VIF-Werte zu berechnen geben wir einfach den folgenden Wert ein:
vif
Dies resultiert in folgendem Output:

In der Spalte VIF ist für jede der 3 unabhängigen Variablen ein VIF-Wert dargestellt. Sie müssen hier darauf achten, ob die VIF-Werte kleiner als 10 sind. Wenn alle VIF-Werte kleiner als 10 sind liegt keine Multikollinearität vor, d.h. die Voraussetzung ist erfüllt. In unserem Beispiel ist zu sehen, dass diese Voraussetzung (sehr knapp) erfüllt ist, da für jede unabhängige Variable ein VIF-Wert von unter 10 vorliegt und somit keine Multikollinearität vorliegt.
2. Homoskedastie prüfen mit Breusch-Pagan-Test
Um zu prüfen, ob die Voraussetzung Homoskedastie (bzw. Homoskedastizität) erfüllt ist, verwenden wir den Breusch-Pagan-Test. Um diesen Test zu berechnen, geben Sie in die Kommandozeile den folgenden Befehl ein:
hettest
Nach Eingabe des Befehls erhelten wir den folgenden Output:

Unten im Output finden Sie den p-Wert des Tests. Dieser liegt bei 0.5276. Da der p-Wert über 0.05 liegt, ist die Voraussetzung erfüllt.
Diese Voraussetzung können Sie anstelle des Breusch-Pagan-Tests auch mit einem Residuals-vs-fitted-Diagramm prüfen.
3. Normalverteilung der Residuen mit Shapiro-Wilk-Test prüfen
Um diese Voraussetzung zu prüfen, müssen Sie zunächst einmal die Residuen der Regression berechnen. Hierzu geben Sie den folgenden Befehl ein:
predict res, resid
Mit diesem Befehl wird im Datensatz eine neue Variable erzeugt, die die Residuen der Regression enthält. Sehen Sie sich die neue erzeugte Variable an, indem Sie den Befehl browse eingeben. Die finden im Datensatz ganz rechts die Variable res. Nun müssen wir prüfen, ob die Residuen normalverteilt sind. Wir verwenden hierzu den Shapiro-Wilk-Test. Um den Test durchzuführen, geben Sie in die Stata-Kommandozeile den folgenden Befehl ein:
swilk res
Sie erhalten hierdurch den folgenden Output:

Rechts im Output finden Sie den p-Wert des Tests. Dier beträgt p=0.16520. Da der p-Wert größer als 0.05 ist, ist die Voraussetzung erfüllt.
Anstatt mit dem Shapiro-Wilk-Test können Sie diese Voraussetzung auch prüfen, indem Sie einen QQ-Plot oder ein Histogramm der Residuen erstellen.
4. Autokorrelation mit Durbin-Watson-Test prüfen
Um zu Prüfen, ob eine Autokorrelation der Residuen vorliegt, wird der Durbin-Watson-Test angewandt. Um diesen Test zu berechnen, geben Sie die folgenden 3 Befehle in die Kommandozeile ein:
gen n=_n
tsset n
estat dwatson
Sie erhalten dadurch den folgenden Output:

Ganz rechts im Output finden Sie den Durbin-Watson-Wert, der hier bei 1.564598 liegt. Wenn dieser Wert nahe bei 2 liegt, ist die Voraussetzung erfüllt. Sie können hierzu eine Faustregel anwenden, wonach die Voraussetzung erfüllt ist, wenn der Durbin-Watson-Wert zwischen 1.50 und 2.50 liegt. Der hier berechnete Wert von 1.56 liegt zwischen 1.50 und 2.50, somit ist diese Voraussetzung erfüllt.
5. Lineare Zusammenhänge mit Streudiagramm prüfen
Um zu prüfen, ob zwischen der abhängigen Variable und den unabhängigen Variablen lineare Zusammenhänge bestehen, werden Streudiagramme verwendet. Diese Voraussetzung ist nur für die metrisch skalierten unabhängigen Variablen relevant, also für weight und length. Für kategorielle unabhängige Variablen muss die Voraussetzung nicht geprüft werden.
Um jeweils ein Streudiagramm für die unabhängigen Variablen weight und length zu erzeugen, geben wir nacheinander die folgenden beiden Befehle ein:
graph twoway (scatter gear_ratio weight)
graph twoway (scatter gear_ratio length)
Durch die Eingabe dieser beiden Befehle erhalten Sie die folgenden beiden Diagramme:

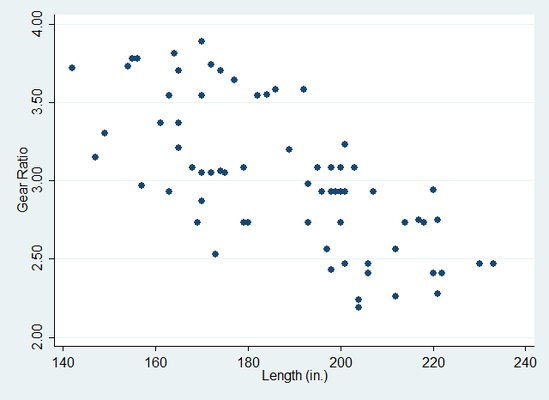
Sie sehen, dass in beiden Graphiken die abhängige Variable gear_ratio auf der y-Achse dargestellt ist. Links ist die unabhängige Variable weight und rechts die unabhängige Variable length auf der x-Achse dargestellt. Es ist zu sehen, dass in beiden Graphiken ein in etwa linearer Zusammenhang zu sehen ist, somit ist die Voraussetzung erfüllt.
Insgesamt sind somit alle Voraussetzungen erfüllt. Beachten Sie, dass wir in diesem Beispiel eine Regression untersucht haben, bei der alle Voraussetzungen erfüllt waren. Das muss natürlich nicht so sein, d.h. es kann vorkommen dass eine oder mehrere Voraussetzungen nicht erfüllt sind.
Falls die Voraussetzungen nicht erfüllt sind, müssen geeignete Maßnahmen getroffen werden. Z.B. kann bei nicht erfüllten linearen Zusammenhängen eine Variablentransformation sinnvoll sein, bei nicht erfüllter Normalverteilung kann eine Winsorierung sinnvoll sein, etc.
Auf diese Verfahren sind wir hier nicht eingegangen, da dies den Rahmen eines Artikels sprengen würde. Die Texte auf unserer Seite werden jedoch in regelmäßigen Abständen erweitert, schauen Sie also am besten zu einem späteren Zeitpunkt noch einmal vorbei!
Mina (Dienstag, 21 Juni 2022 23:12)
Top Erklärung, wäre sonst so verloren ey!