
Varianzanalyse (ANOVA) mit Stata
Auf dieser Seite finden Sie eine Anleitung zur Durchführung einer zweifaktoriellen Varianzanalyse (Two-Way-ANOVA) mit Stata. Die zweifaktorielle Varianzanalyse ist eine Methode, mit welcher der Einfluss zweier nominaler Variablen auf eine abhängige metrische Variable untersucht werden kann.
Um das Beispiel nachzuvollziehen laden Sie den folgenden Beispiel-Datensatz im Stata-Format herunter:
Nach dem Download befindet sich der Datensatz in Ihrem Downloads-Ordner. um die Datei zu öffnen, gehen Sie in Ihre Downloads-Ordner und doppelklicken Sie auf die Datei. Der Datensatz ist nun in Stata eingelesen.
Sehen Sie sich den Datensatz zunächst im Dateneditor an. Geben Sie hierzu den Befehl edit ein. Sie erkennen nun, dass der Datensatz die Variablen Y, X1 und X2 enthält:
Wir möchten nun eine Varianzanalyse berechnen, um den Effekt von X1 und X2 auf Y zu untersuchen. Dazu geben wir den folgenden Befehl ein:
anova Y X1 X2 X1#X2
Die erste im Anova-Kommando eigegebene Variable (Y) kennzeichnet die abhängige Variable. X1 und X2 sind die unabhängigen Faktoren und X1#X2 die Interaktion von X1 und X2. Der Befehl erzeugt den folgenden Output:
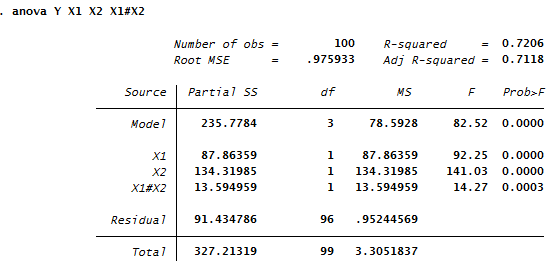
Wir sind an den Effekten der einzelnen Variablen interessiert, weshalb wir die F-Werte und p-Werte der Tabelle examinieren, die für jeden Faktor in der Tabelle enthalten sind. Es stellt sich hier zunächst die Frage, wie die F-Werte und p-Werte interpretiert werden sollen.
Der F-Wert ist die Prüfgröße des F-Tests. Für den F-Wert braucht man lediglich zu wissen, dass der F-Wert umso größer ist, je stärker der Einfluss des jeweiligen Faktors ist. Es gibt aber keine allgemeine Regel, ab wann ein F-Wert als groß oder signifikant anzusehen ist, da dies von der Stichprobe und der Anzahl an Faktoren in der ANOVA abhängt.
Die wichtigere Kennzahl ist der p-Wert. Für diesen Wert gilt die Konvention, dass immer dann von einem statistisch signifikanten Effekt gesprochen wird, wenn der p-Wert kleiner als 0.05 ist. Man erkennt z.B. in obiger Output-Tabelle, dass der p-Wert von X1 den Wert p=0.00 annimmt, woraus wir schließen, dass der Faktor X1 einen signifikanten Effekt auf Y ausübt.
Was die schriftliche Darstellung der Ergebnisse dieser ANOVA angeht, so hat sich für die F- und p-Werte eine bestimmte Art der Darstellung eingebürgert. In einem Artikel würden wir den Effekt von X1 folgendermaßen angeben:
Der Faktor X1 zeigt mit einem F-Wert von F(1,96)=92.25, p< 0.001 einen signifikanten Einfluss auf Y.
Man stellt also zunächst den F-Wert, und dann den p-Wert dar. Die Zahlen innerhalb der Klammern, also bei F(1,96), sind die Freiheitsgrade. Diese wurden aus obiger Tabellen entnommen, und zwar aus den Zeilen X1 und Residual. Eine häufig gestellte Frage ist die nach Sinn der Freiheitsgrade. Eine genaue Erläuterung würde den Rahmen dieses Artikels sprengen, es sei aber erwähnt dass die Angabe der Freiheitsgrade eigentlich keinen Erkenntniszuwachs mit sich bringt, sondern es schlicht "Konvention" ist sie mit anzugeben. Wir empfehlen Ihnen daher, sich über den Sinn der Freiheitsgrade nicht zu viele Gedanken zu machen.
Beachten Sie außerdem, dass wir den p-Wert im obigen kursiv gedruckten Satz den p-Wert in der Form p < 0.001 angegeben haben. Dies ist ebenfalls eine Konvention und wird damit begründet dass der p-Wert von Statistik-Programmen häufig auf Null abgerundet wird, jedoch eigentlich aus mathematischen Gründen jedoch nicht Null werden kann. Daher wäre die Angabe p=0.00 falsch, und man gibt stattdessen p < 0.001 an.
Betrachten wir nun den anderen Faktor X2 als auch die Interaktion von X1 und X2 und stellen wir die Ergebnisse in der eben gelernten Form dar:
Weiterhin zeigt auch der Faktor X2 mit einem F-Wert von F(1,96)=141.03, p < 0.001 einen signifikanten Effekt auf die Variable Y. Ebenso liegt eine signifikante Interaktion der beiden Faktoren vor (F(1,96)=14.27, p < 0.001).
Wir erkennen also, dass X2 ebenfalls einen Effekt auf Y ausübt. Was die Interaktion angeht, so bedeutet diese, dass die Effekte der beiden Faktoren auch voneinander abhängen, was weiter untern näher erläutert wird.
Beachten Sie nun noch folgendes: Wir haben zwar herausgefunden, dass die Faktoren X1 und X2 jeweils einen signifikanten Einfluss auf Y haben, aber die ANOVA macht keine Aussage darüber, in welche Richtung der Effekt geht, also z.B. welche Ausprägung von X1 ein höheres oder ein niedrigeres Y bewirkt.
Um dies herauszufinden, sollten zusätzlich zu den bisher durchgeführten Analysen die sogenannten marginalen Mittelwerte berechnet werden. Berechnen wir z.B. die marginalen Mittelwerte für den Faktor X1. Hierzu geben wir nach der Berechnung der ANOVA folgenden Befehl ein
margins X1
und erhalten diesen Output:

Die geschätzten Randmittel (engl.: predictive margins) sind die durch das Modell prognostizierten Werte der abhängigen Variable Y für die einzelnen Ausprägungen des unabhängigen Faktors. Wir erkennen hier, dass für X1 = 1 die abhängige Variable den Wert 0.293 annimmt. Für X1 =2 hingegen prognostiziert das Modell für Y einen Wert von 2.167.
Falls Sie sich für eine Nachhilfe / Beratung bezüglich Stata oder eine Auswertung mit Stata interessieren, nehmen Sie Kontakt zu uns auf.
Weitere Informationen finden Sie hier: Stata Beratung & Nachhilfe.